
Hi! I am now a Member of Technical Staff at xAI. I was a Research Scientist at Meta SuperIntelligence Lab, and a Principal Researcher at MSR.
My current research is focused on building generalist multi-modal models. We are the first few in this line of research and have produced a series of works, including (a) multimodal vision foundation models: UniCL, RegionCLIP, GLIP, large-scale foundation model Florence; (b) generalist multimodal models X-Decoder, SEEM, Semantic-SAM and (c) large multimodal models LLaVa variants, SoM Prompting for GPT-4V, and Phi-3-Vision.
Most recently, I led Project Magma, the flagship project at MSR towards multimodal ai agents. The project was ranked #1 on Hacker News on February 20, 2025, reflecting its broad impact and interest. Looking ahead, I’m committed to the next wave of progress—building intelligent agents that are not only high-performing but also grounded, interpretable and reliable across modalities.
Research News
[02/2025] We released Magma, the flagship project at MSR towards multimodal agentic foundation! A single model can serve multimodal understanding and action-taking seamlessly. Check it out!
[01/2025] We released TraceVLA applying visual trace prompting to enchance the spatial-temporal awareness of vision-language-action models for robotics manipulation task!
[12/2024] Florence-VL studied the potential of generative pretrained vision tokenizer for LMMs, OLA-VLM elevated the vision perception capabilities for LMMs by distilling the visual knowledge into LLMs!
[11/2024] We released OmniParser models and code (5.5k stars), a pure vision based UI parser for computer use!
[10/2024] We proposed LAPA, the first work that learns latent actions from videos in the wild for robot manipulation!
[10/2024] We released TemporalBench for evaluating LMMs the fine-grained understanding of temporal dynamics in videos!
[09/2024] BiomedParse is accepted by Nature Methods and GigaPath got accepted by Nature! Big congratulations to Health Future team and cheers on the great collaborations!
[05/2024] We announced Phi-3-Vision, a 4.2B parameter multimodal model with language and vision capabilities! [blog] [hugging face]
[10/2023] We released Set-of-Mark (SoM) prompting to unleash the extraordinary visual grounding power in GPT-4V. Come and try our SoM toolbox!
Academic Activities
[03/2025] Invited to give a talk about Magma: A Foundation Model for Multimodal AI Agents at OpenAI Robotics team.
[12/2024] Gave a talk “Towards Multimodal Agentic Models that Understand the Past and Act for the Future” at NeurIPS 2024 1st Workshop on Video-Language Models.
[09/2024] Have a great panel discussion about the next generation multimodal models at Microsoft Research Forum Session 4 on Multimodality.
[07&08/2024] Serve as an Area Chair for NeurIPS 2024 and ICLR 2025.
[06/2024] Gave a tutorial on “A Close Look at Vision in Large Multimodal Models” [slides] [youtube] at CVPR 2024 Tutorial on Recent Advances in Vision Foundation Models.
[06/2024] Gave a keynote talk on “Promptable Vision Foundation in the Wild: From Head to Tail” at CVPR 2024 Worshop on Computer Vision for Materials Science.
[06/2024] Organized the 3rd Computer Vision in the Wild (CVinW) Workshop at CVPR 2024.
[05&06/2024] Invited talk on “Towards General-Purpose Multimodal Agent” at University of Washington and Together AI.
[07/2023] Panel Discussion on AI Frontier at WAIC and invited talk on “Towards General-Purpose Multimodal Agent” at IDEA.
[06/2023] Gave a tutorial on “From Representation to Interface: The Evolution of Foundation for Vision Understanding” [slides] [youtube] at CVPR 2023 Tutorial on Recent Advances in Vision Foundation Models.
[03/2023] We are announcing the 2nd Computer Vision in the Wild (CVinW) Workshop at CVPR 2023!
[12/2022] Served as an Area Chair for ICCV 2023.
[06/2022] Gave a tutorial on “Vision Language Pretraining for Image Classification” [slides] [youtube] at CVPR 2022 Tutorial on Recent Advances in Vision-and-Language Pretraining.
Selected Preprints
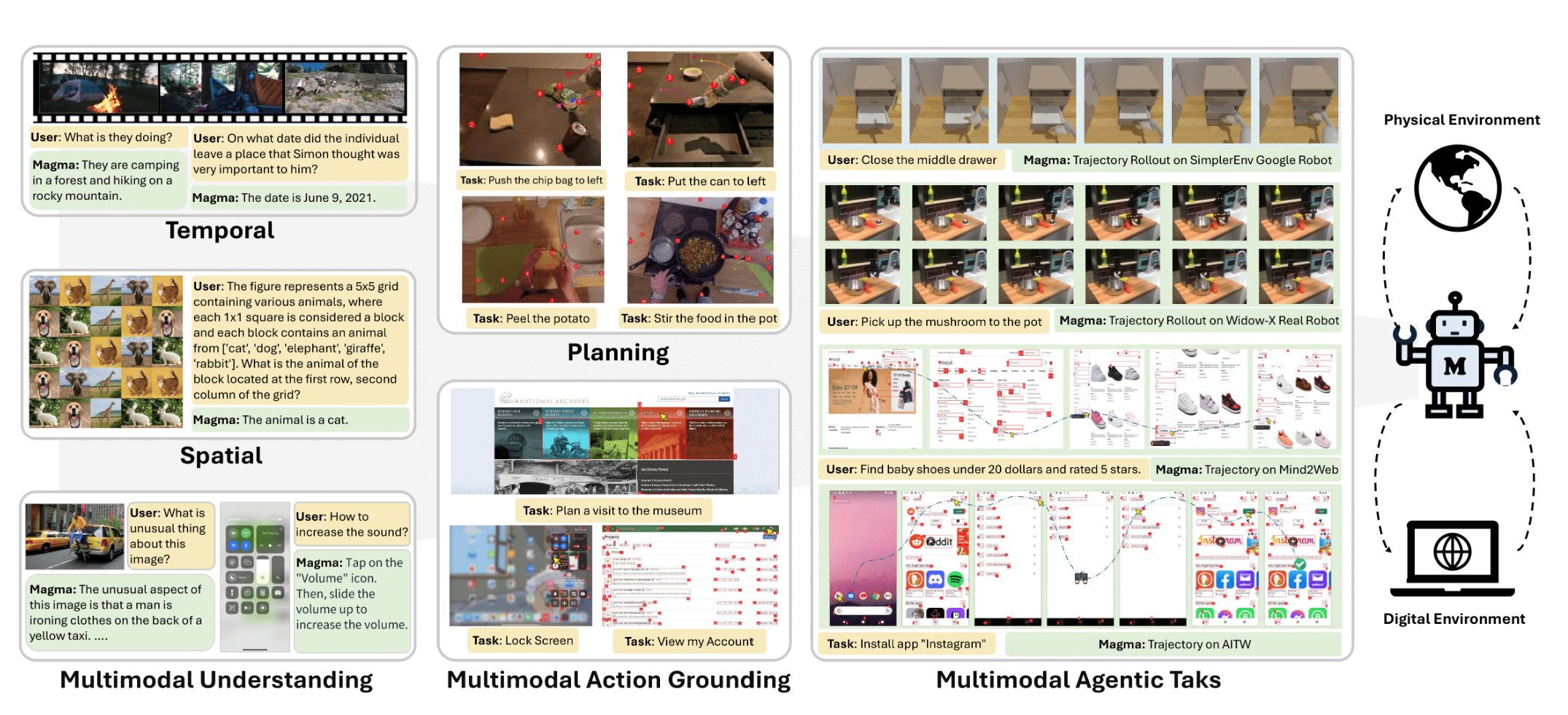 | Magma: A Foundation Model for Multimodal AI Agents.Magma Team.arXiv, 2025 |
 | Phi-3 technical report: A highly capable language model locally on your phone.Phi-3-Vision Team.arXiv, 2024 |
 | Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V.Jianwei Yang*☨, Hao Zhang*, Feng Li*, Xueyan Zou*, Chunyuan Li, Jianfeng Gao.arXiv, 2023 |
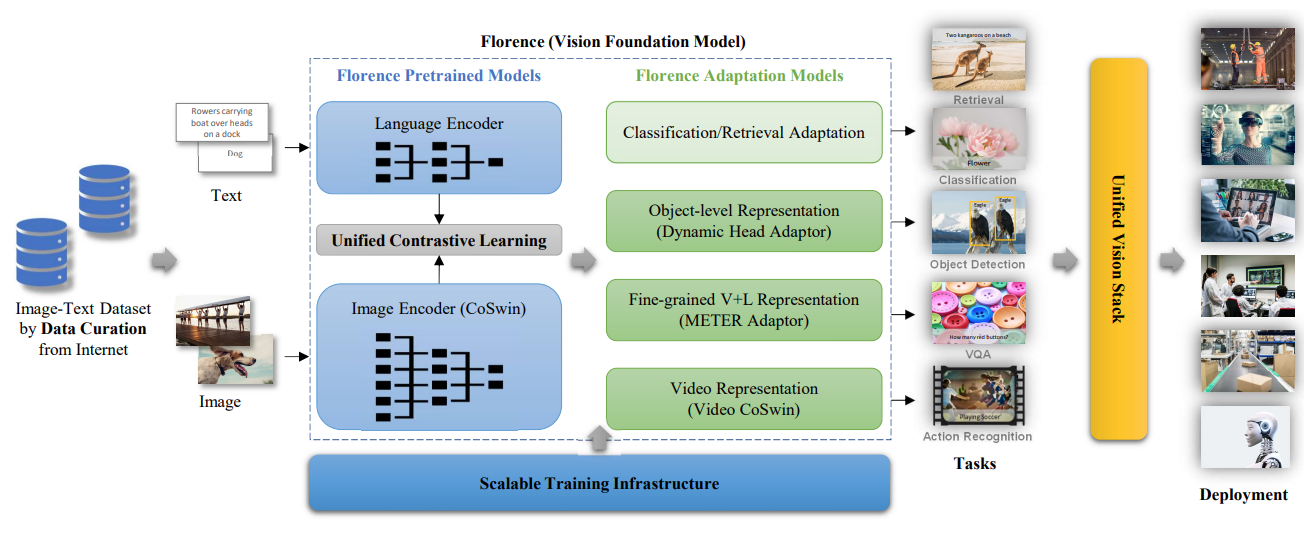 | Florence: A new foundation model for computer vision.Florence Team.arXiv, 2021 |
Selected Publications
 | Semantic-SAM: Segment and Recognize Anything at Any Granularity.Feng Li*, Hao Zhang*, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang^, Chunyuan Li, Lei Zhang☨, Jianfeng Gao☨.ECCV, 2024 |
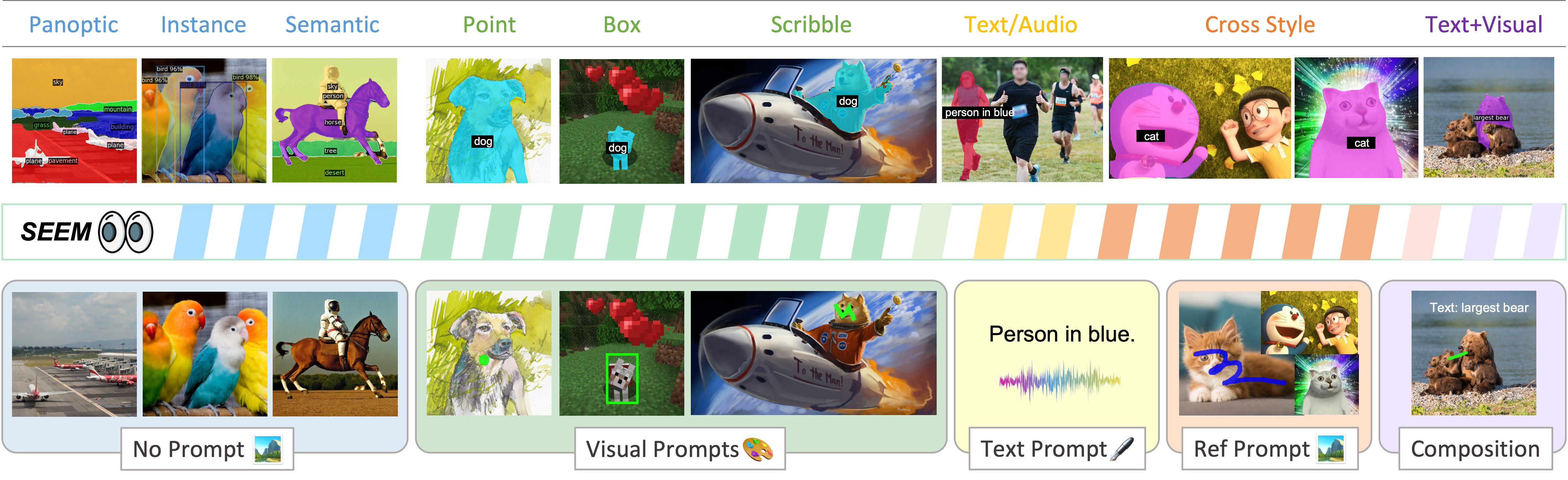 | Segment Everything Everywhere all at Once.Xueyan Zou*, Jianwei Yang*^, Hao Zhang*, Feng Li*, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao☨, Yong Jae Lee☨.NeurIPS, 2023 |
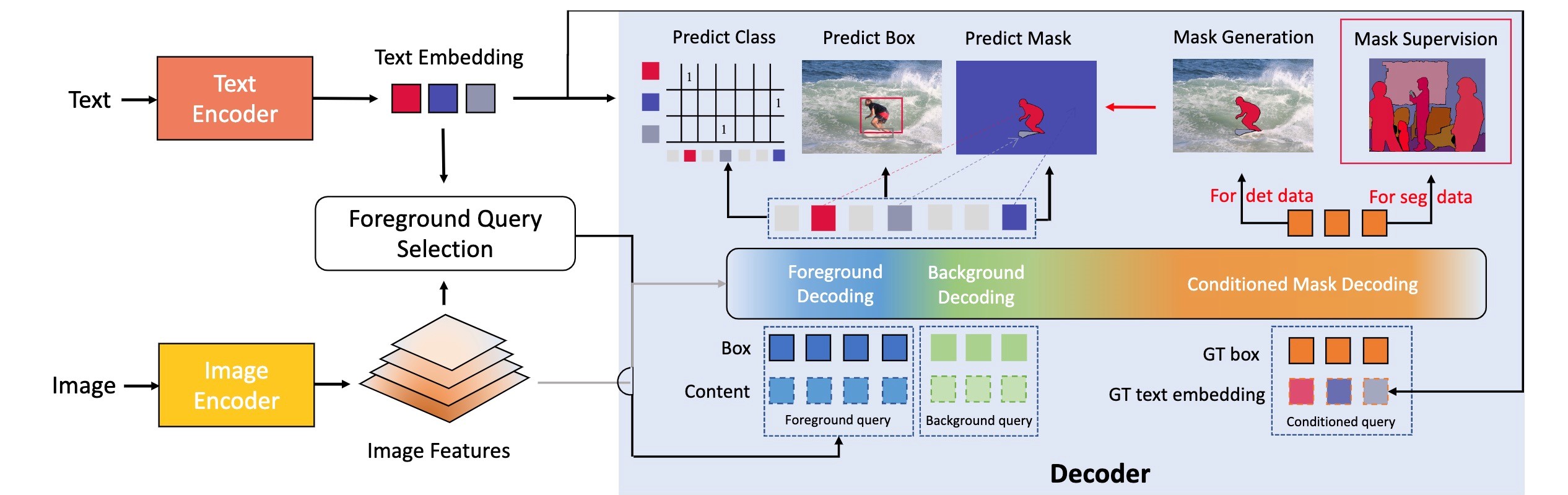 | A Simple Framework for Open-Vocabulary Segmentation and Detection.Hao Zhang*, Feng Li*, Xueyan Zou, Shilong Liu, Chunyuan Li, Jianfeng Gao, Jianwei Yang☨, Lei Zhang☨.ICCV, 2023 |
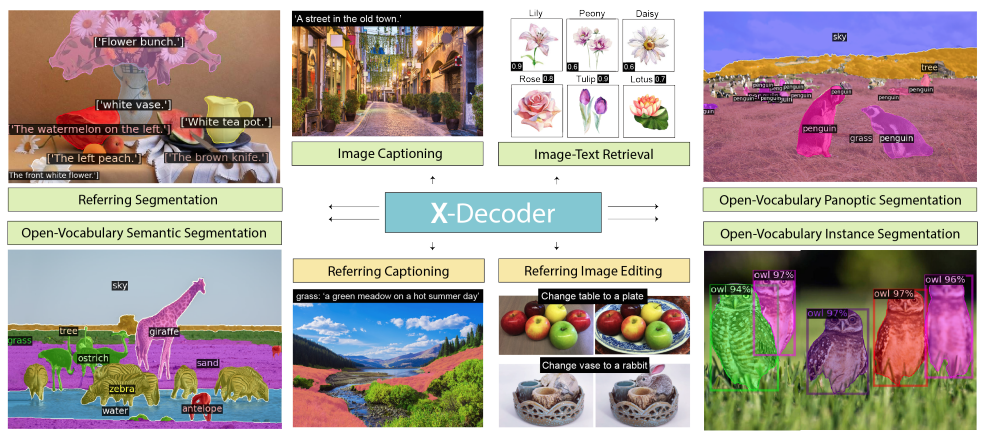 | Generalized Decoding for Pixel, Image, and Language.Xueyan Zou*, Zi-Yi Dou*, Jianwei Yang*, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, Nanyun Peng, Lijuan Wang, Yong Jae Lee☨, Jianfeng Gao☨.CVPR, 2023 |
 | Focal Modulation Networks.Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan and Jianfeng Gao.NeurIPS, 2022 |
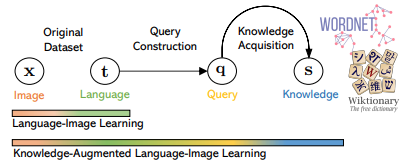 | K-lite: Learning transferable visual models with external knowledge.Sheng Shen*, Chunyuan Li*, Xiaowei Hu, Yujia Xie, Jianwei Yang, Pengchuan Zhang, Anna Rohrbach, Zhe Gan, Lijuan Wang, Lu Yuan, Ce Liu, Kurt Keutzer, Trevor Darrell, Jianfeng Gao.NeurIPS, 2022. Oral |
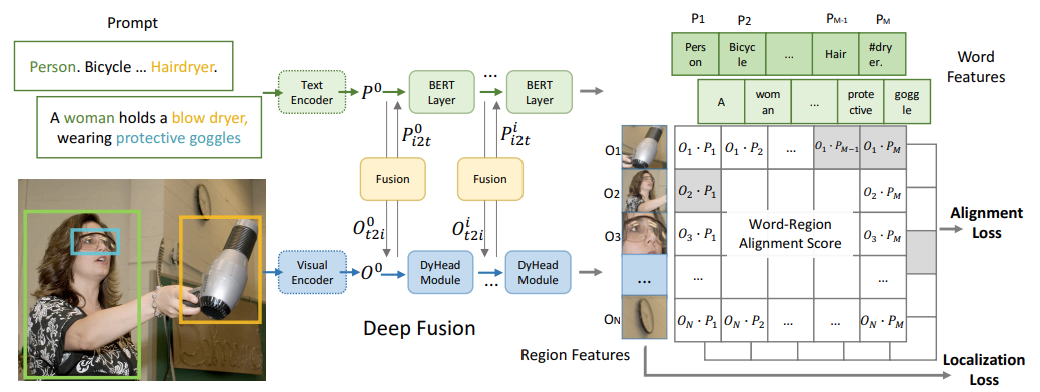 | Grounded language-image pre-training.Liunian Harold Li*, Pengchuan Zhang*, Haotian Zhang*, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, Jianfeng Gao.CVPR, 2022. Best Paper Final list |
 | Regionclip: Region-based language-image pretrainingYiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, Jianfeng Gao.CVPR, 2022 |
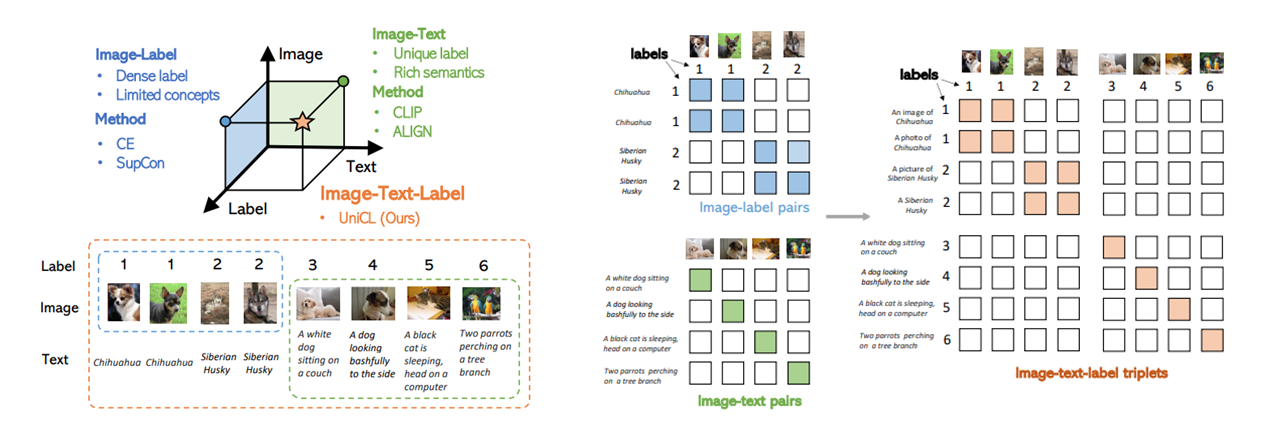 | Unified contrastive learning in image-text-label space.Jianwei Yang*, Chunyuan Li*, Pengchuan Zhang*, Bin Xiao*, Ce Liu, Lu Yuan, Jianfeng Gao.CVPR, 2022 |
 | Efficient self-supervised vision transformers for representation learning.Chunyuan Li, Jianwei Yang, Pengchuan Zhang, Mei Gao, Bin Xiao, Xiyang Dai, Lu Yuan, Jianfeng Gao.ICLR, 2022 |
| | Focal attention for long-range interactions in vision transformers.Jianwei Yang, Chunyuan Li, Pengchuan Zhang, Xiyang Dai, Bin Xiao, Lu Yuan, Jianfeng Gao.NeurIPS, 2021, Spotlight. |
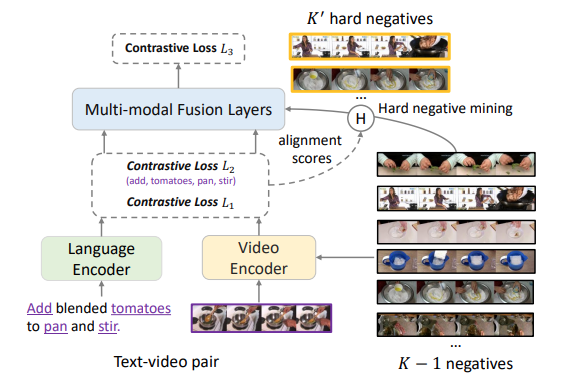 | Taco: Token-aware cascade contrastive learning for video-text alignment.Jianwei Yang, Yonatan Bisk, Jianfeng Gao.ICCV, 2021 |